
The next stage of LLMs: retrieval systems, models and prompt engineering
This is the second piece in a three-part blog by Olivier Mills of Baobab Tech, a Frontier Tech implementing Partner
Pilot: Using LLMs as a tool for International Development professionals
Part 2: Retrieval systems, models and prompt engineering
In the previous part, we explored the technical environment and data preparation for our LLM application. Now, we'll dive into the heart of our system: building effective retrieval mechanisms, choosing LLMs and exploring prompt engineering.
4. Building the retrieval system
After data preparation, building an effective retrieval system is probably the most important part of the system to ensure it meets user needs. This section delves into the various techniques and experiments we conducted to create a robust Retrieval-Augmented Generation (RAG) system.
4.1 RAG techniques and experimentation
The landscape of RAG approaches is vast and rapidly evolving. LangChain docs on Retrieval explain these rather well (as of June 2024). Just recently, the HippoRAG technique emerged, claiming to mimic the human brain and memory system. If you take the time to read the paper you’ll see it’s essentially a method for building dynamic, schemaless Knowledge Graphs.

Source: LangChain (https://js.langchain.com/v0.2/docs/concepts/#retrieval)
We are exploring several RAG approaches, each with increasing complexity and capability:
Basic RAG: This fundamental approach involves vectorizing document chunks, using semantic similarity for retrieval, and generating answers with an LLM based on the query and retrieved context. While simple, it's effective for basic information extraction and question-answering tasks.
Advanced RAG: This method implements hierarchical indexing with metadata-rich chunks, query expansion techniques, and context curation via LLM-based filtering or ReRankers. It enhances relevance and coherence through sophisticated pre- and post-retrieval optimization.
Modular RAG: This approach incorporates structural indexing, metadata-enriched chunking, and specialized query rewriting. It implements iterative retrieval with feedback loops and leverages domain-specific LLMs for generation.
Single-Agent RAG: This technique integrates planning methods like Task Decomposition or PLaG, implements tool use for expanded information gathering, and employs self-reflection for answer generation. It enhances answer quality through metacognitive processes and adaptive information seeking.
Multi-Agent RAG: This advanced approach utilizes Rewrite-Retrieve-Read query optimization, implements adaptive retrieval based on confidence scores, and employs a horizontal multi-agent architecture with a shared knowledge base. It leverages specialized LLMs for diverse tasks, enhancing retrieval and generation through collaborative agent interactions.
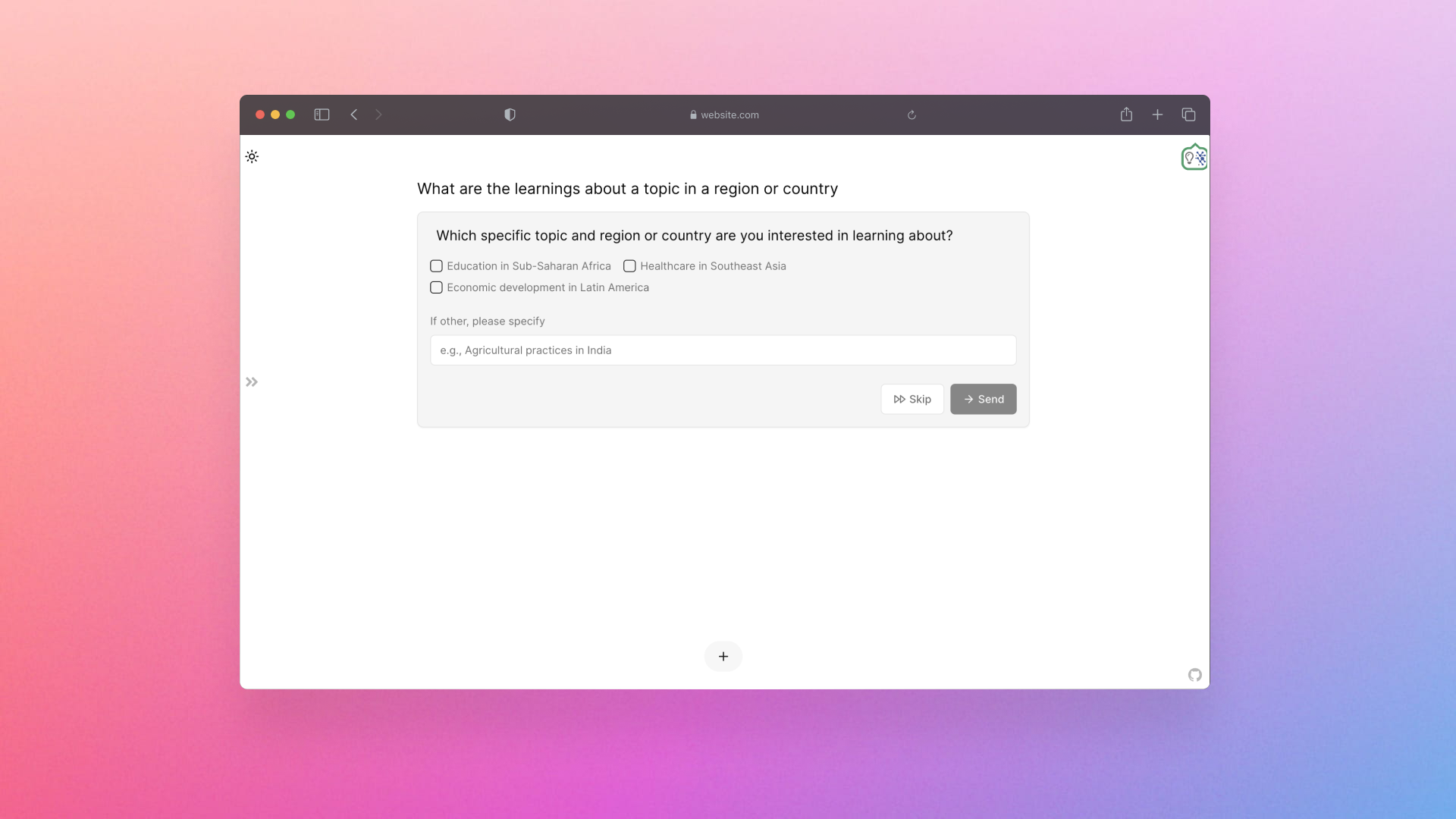
UI component showing the “Ask-a-human” call from the agentic AI system when the user’s query is vague before doing any search or retrieval
Through our experimentation for our specific use-cases, we identified several key learnings. Naive or vanilla RAG (simple chunking and vector search) is insufficient for complex user queries and tasks. Effective RAG requires, at a minimum:
Larger chunking techniques, preferably at least page-level.
LLMs with larger context windows (e.g., GPT-4o, Llama-3.1-70b, Gemini, or Mistral-5x22b) to handle 1000 to 5000 word chunks per result and filter out noise.
Query decomposition for multi-faceted questions. For instance, a query like "What are the different programmes that cover humanitarian and nutrition in Africa and Asia?" should be broken down into multiple searches (e.g., "humanitarian programmes Africa", "humanitarian nutrition programmes Asia") for richer results.
Hybrid search combining sparse vector (keyword) and dense vector (embeddings) approaches, with up-ranking for items appearing in both.
Re-ranking to improve relevance and push less pertinent items to the long tail of large searches.

Query re-write with parallel hybrid retrieval
4.2 Embeddings
In modern RAG systems, hybrid search strategies combining vector and keyword search have become the norm. However, the choice of what text to vectorize and use for keyword search significantly impacts quality.
For our system, we created a concatenated summary of activity/programme data in a summary field, which is then used for a stored Full-Text Search (FTS) field. We implemented this using a simple PostgreSQL tsvector:

This approach updates the FTS field with a tsvector of the summary. For more advanced implementations, a weighted approach or a BM25 sparse vector technique could be considered. We might experiment with this or the very new BMX (https://arxiv.org/abs/2408.06643) which incorporates entropy-weighted similarity and semantic enhancement techniques.
When choosing embedding models, we opted for OpenAI's text-embedding-3 with reduced dimensions of 256. This decision was based on the understanding that more dimensions aren't always necessary and can be costly at scale. For multilingual applications, we recommend the BGE-m3 model. We are likely to shift to open-models such as MXBAI-large or BGE-large which are currently better than OpenAI’s (see the MTEB leaderboard) - note that everyday, new embedding models are being released and doing better.
It's worth noting that dimensions above 1000 are often overkill for most RAG vector searches. This insight is supported by research from Cohere (int8-binary-embeddings) and Jina AI (binary-embeddings). We plan to explore binary/1-bit embeddings as we scale to the full IATI dataset and beyond as this would enhance performance, speed, reduce cost and storage.. without affecting quality.
After experimenting with various vector databases (e.g., Weaviate, Qdrant, Pinecone), we decided on a flexible approach using PostgreSQL with pgvector v0.7. This setup includes HNSW indexing and allows for multiple vector columns, including FTS (tsvector) and retrieval functions. It also provides the flexibility to create a more relational database with different data components.
There's ongoing discussion about whether dense vectors (using "larger" embedding models) are necessary for RAG, or if properly designed sparse vectors could suffice. We're currently testing this by analyzing how often retrieved items come from dense vector versus sparse/ts vector searches in our hybrid approach.
Interesting to note is that while LLM application techniques seem cutting-edge, many underlying concepts aren't new. The vector space model, for instance, was invented in the 1960s. Dense vectors only gained popularity in the 2010s with the rise of deep learning.
4.3 Fine-tuning
Like many others in the midst of building LLM applications, we often face the decision of whether to fine-tune a model. While this process can be less daunting than expected (as discussed in this post), we haven't found it necessary for our current use cases, yet.
The one potential exception where fine-tuning might be beneficial is fine-tuning a 2 to 8 billion parameter model specifically for query decomposition. This could potentially improve the efficiency and accuracy of breaking down complex queries into more manageable sub-queries specific to this subject mater and the use-cases we expect, that said the right prompt with the right model might be all we need.
5. Prompt engineering
Prompt engineering is a critical skill in developing effective LLM applications. If you haven't invested significant time in fine-tuning your prompts, you’ll likely have more work ahead. The art of crafting prompts to suit specific tasks is a learned skill that requires patience and experimentation. Most language models are left completely underutilised because of poor or lazy prompting.
This skill becomes particularly crucial when working with smaller models (those with fewer than 70 billion parameters). It's why many prototypes and proofs of concept for LLM applications rely on state-of-the-art models like GPT-4o or Claude 3.5 Sonnet. While these models are powerful and more lenient to lazy prompts, they're also expensive and may not be viable for applications intended to scale to thousands of users.
When working with smaller models, prompts tend to be more sensitive to changes. A prompt that works well for Llama-3.1-8b may not be effective for Gemini-Flash, Gemma, Command-R, or GPT-4o-mini. Each model change necessitates testing and revising your prompts. Conversely, larger models are generally less sensitive to prompt nuances, allowing for more flexibility in wording and structure.
5.1. Prompts for query decomposition
Here's an example of a prompt template we use to break down complex user questions:

This prompt is verbose because we're using a smaller model (Llama-3.1-8b). While a larger, more capable and more expensive model could potentially use a simpler prompt, it's important to consider costs at scale. There's always at least one query decomposition call per request, so efficiency is key.
Note the conditional "context" in the prompt. This allows us to inject context for follow-up questions. For instance, if the follow-up is "explain lessons learned for that programme," we can inject the programme name as context. Without this, the query decomposition might be less effective without know what “that” is. An alternative to context injection is using message history, where you add chat history to allow the LLM to infer context. However, this significantly increases costs and ties the system to a chat-based (user/assistant turn-taking) approach.
5.2. (Prompt) Context Caching
Context caching is an innovative technique recently introduced by major players like Anthropic (feature in beta in August 2024) and Google, allowing developers to store and reuse specific contextual information within prompts. This approach can slash costs by up to 90% and improve response times by up to 2x in certain scenarios, particularly for applications involving long instructions, uploaded documents, or multiple rounds of tool calls.
For us, context caching holds immense potential. Our application requires analyzing full contents of documents for multiple analyses, which can be costly at scale. By implementing context caching, we could dramatically reduce costs and improve efficiency in several key areas:
Document Analysis: Caching content of lengthy programme documents or evaluation reports for reuse across multiple queries.
Portfolio Analysis: Storing relevant programme details and contextual information for efficient comparative analyses.
Contextualized Summaries: Reducing cost and time for generating relevancy summaries in large result sets (e.g., 40-100 activities).
While implementing context caching would involve a slightly higher initial cost for writing to the cache, the significant reduction in subsequent read costs aligns well with our need to optimize for scale. As we expand to cover larger datasets like the full IATI database or incorporate additional sources, context caching could be crucial in making our application more scalable and cost-effective and nuanced with more context, setting a new standard for AI-assisted decision-making tools.
Stay tuned for the next part soon on UI Development, Future Directions, and Applications
If you’d like to dig in further…
🚀 Explore this pilot’s profile page
📚 Learn more about the idea behind the pilot here
📚 Read part one of the blog here
📚 Read part three of the blog here